Gaussian Stochastic Weight Averaging for Bayesian Low-Rank Adaptation of Large Language Models
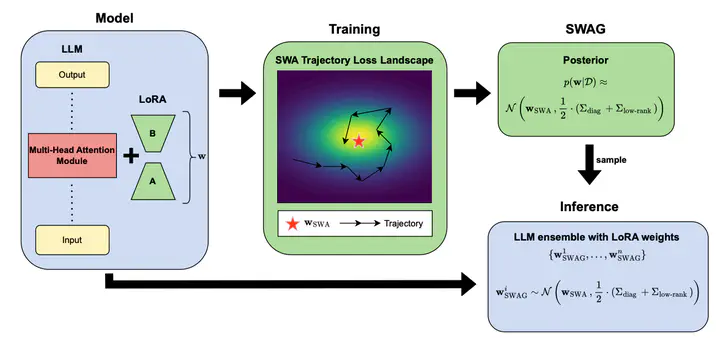 Outline of the SWAG-LoRA training and inference process. The left panel shows the LLM architecture with LoRA fine-tuning. The middle and upper right panel depict the SWAG training process, where weight samples are collected across iterations of SGD to calculate the mean and an approximate covariance of the posterior over network weights. The lower right panel demonstrates how we form our ensemble of weights for inference by sampling from the learned SWAG posterior.
Outline of the SWAG-LoRA training and inference process. The left panel shows the LLM architecture with LoRA fine-tuning. The middle and upper right panel depict the SWAG training process, where weight samples are collected across iterations of SGD to calculate the mean and an approximate covariance of the posterior over network weights. The lower right panel demonstrates how we form our ensemble of weights for inference by sampling from the learned SWAG posterior.Abstract
Fine-tuned Large Language Models (LLMs) often suffer from overconfidence and poor calibration, particularly when fine-tuned on small datasets. To address these challenges, we propose a simple combination of Low-Rank Adaptation (LoRA) with Gaussian Stochastic Weight Averaging (SWAG), facilitating approximate Bayesian inference in LLMs. Through extensive testing across several Natural Language Processing (NLP) benchmarks, we demonstrate that our straightforward and computationally efficient approach improves model generalization and calibration competitively with comparable, more sophisticated methods for Bayesian inference in LLMs. We further show that our method exhibits greater robustness against distribution shift, as reflected in its improved performance on out-of-distribution tasks.
This paper presents a novel approach to improving the calibration and generalization of Large Language Models by integrating Gaussian Stochastic Weight Averaging with Low-Rank Adaptation. Extensive evaluations on NLP benchmarks highlight its effectiveness in addressing overconfidence and distribution shifts. The method provides a computationally efficient and robust alternative to existing Bayesian inference techniques for fine-tuned LLMs.
View the paper on arXiv or explore the GitHub repository for implementation details.